Recentemente comecei a estudar sobre computação paralela e distribuída. O foco principal é melhorar meu entendimento sobre paralelização a nível de nó (máquina) e tirar o melhor proveito do hardware existente, estou bem interessado em HPC (High Performance Computing). Tenho um pequeno artigo para escrever sobre SpMV (Sparse Matrix-Vector Multiplication) e precisava tentar escrever dois algoritmos para esse problema para entender o quanto um código sequencial pode ser mais devagar que um rodando em paralelo e se existe uma forma melhor de fazer isso ou não.
Para metrificar isso, o speedup, a eficiência paralela e a Lei de Amdahl são métricas fundamentais (clássicas) para análise de velocidade e eficiência para os algoritmos, porém acabamos desconsiderando outros detalhes importantes do hardware onde está sendo rodado. Com a necessidade de ter um modelo que conseguisse expressar melhor os detalhes de gargalo de desempenho surge o Roofline model em um artigo publicado por Samuel Williams, Andrew Waterman, and David Patterson de Berkeley.
Roofline e simplificação do hardware
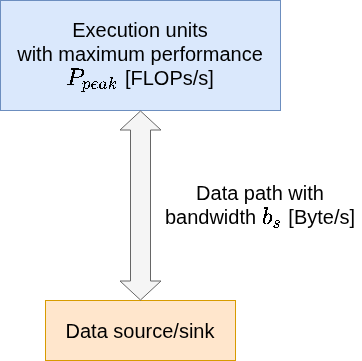
Podemos olhar para o hardware de uma forma mais simplificada em duas partes: unidades de execução onde a CPU realiza operações aritméticas, floating-point em tempo de clock que são representadas por Ppeak ou FLOPS. Isso basicamente representa a quantidade de operações de ponto flutuante (é qualquer cálculo matemático como adição, subtração, multiplicação ou divisão envolvendo números reais) executadas em um determinado tempo, nesse caso FLOP/s.
A outra parte são as fontes de dados que são armazenadas, seja na memória ou mais próxima do chip como os caches, onde esses dados possuem uma largura de banda por onde devem passar. Ou seja, possui um canal limitado de dados que trafegam até a CPU que irá realizar as operações, representado na imagem como bs, cuja unidade na prática é Byte/s.
Agora podemos também olhar para o software que durante o artigo eles consideram uma simplificação e isolam o problema no seu Kernel. Ou seja, o ponto em que os loops existentes em um programa vão realizar seus FLOPs. Em casos de loops, N FLOPs serão executados e uma quantidade V Bytes de dados serão necessários para essa execução. Podemos então considerar uma relação entre esses dois valores (N FLOPs e V Bytes) como sendo uma razão de N e V. Chamamos isso de intensidade operacional, cuja unidade é FLOP/Byte, ficando a relação assim:
Então, podemos considerar que estamos querendo saber a quantidade de FLOP/s que podem ser executados pelo hardware. Na visão simplificada podemos considerar apenas dois gargalos: sua CPU que executa operações em um máximo de Ppeak, ou o sistema será limitado à largura de banda pelo número máximo de Bytes que podem trafegar até a CPU para realizar a operação. Ou seja, podemos considerar que existem dois limites superiores para o cenário:
- Quantidade máxima de operações: Ppeak [FLOP/s]
- Caminho de dados: I [FLOP/Byte] · bs [Byte/s]
Onde I é a quantidade de operações que podem ser executadas no código e bs a quantidade de Bytes que podem trafegar. Multiplicando os dois podemos obter o limite na transferência de dados.
Portanto, em algum momento seremos limitados por esses dois limites. Logo, podemos considerar que o mínimo dos dois é o nosso limite superior para o máximo de performance:
Plotando um gráfico simplificado para representar essas duas funções:
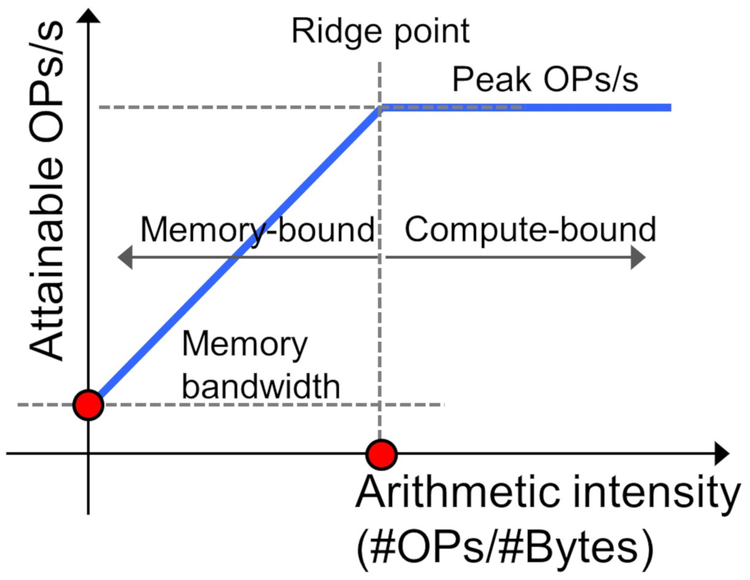
Nesse gráfico podemos analisar as duas funções: a primeira (Peak) é uma constante na qual representa o limite computacional e a segunda (uma função linear I · bs) indica a limitação de memória. O ridge point é o encontro das funções. Caso a aplicação esteja à esquerda, seu código será limitado pela memória (Memory-bound); à direita, será limitado por operações (Compute-bound).
Com isso podemos simplificar e considerar que em alta intensidade (à direita) somos limitados pela computação e em baixa intensidade (à esquerda) somos limitados pela transferência de dados. Podemos considerar também que o ridge point é o máximo de eficiência do hardware, ou seja, estamos usando o máximo de memória e computação existente no sistema. Vale a observação de que este ponto também exige o máximo de energia que o hardware consegue utilizar, pois todos os canais estarão em uso.
Mapeamento da Topologia e Parâmetros da Máquina
Dado isso, vou tentar aplicar isso em meu modelo de hardware. Para isso vou utilizar o likwid, uma ferramenta para entender com mais detalhes minha topologia, porém para efeitos menos detalhistas podemos utilizar o lscpu diretamente do Linux. Rodando o likwid-topology obtive o resultado de que o sistema conta com um processador Intel Core i7-13650HX, com 14 cores físicos, suporte a 2 threads por core, além de uma estrutura de caches contendo L1 de 48 kB, L2 de 1.25 MB e L3 compartilhado de 24 MB.
Vamos utilizar dois parâmetros de máquina principais: Ppeak [FLOP/s] e bs [Byte/s], além da intensidade operacional do código I = F / B. Coletando as informações com o benchmark do likwid, buscamos encontrar primeiramente os "tetos" do hardware. Começando com o limite de banda de memória principal rodando o likwid-bench com o teste copy em 1 thread:
$ likwid-bench -t copy -W N:2GB:1
...
MByte/s: 22358.36
Olhando para a métrica de MByte/s, sabemos que a largura de banda máxima de memória medida para esse barramento (usando apenas 1 thread) é de aproximadamente 22.36 GB/s (22358.36 MB/s).
Agora falta descobrirmos o outro limite: o pico de performance computacional da CPU (o topo horizontal do teto). Como o teste anterior foi de cópia de memória, ele não executa operações aritméticas. Rodando o benchmark para o limite computacional com instruções de ponto flutuante vetorizadas:
$ likwid-bench -t peakflops_avx_fma -W N:2GB:1
...
MFlops/s: 55288.73
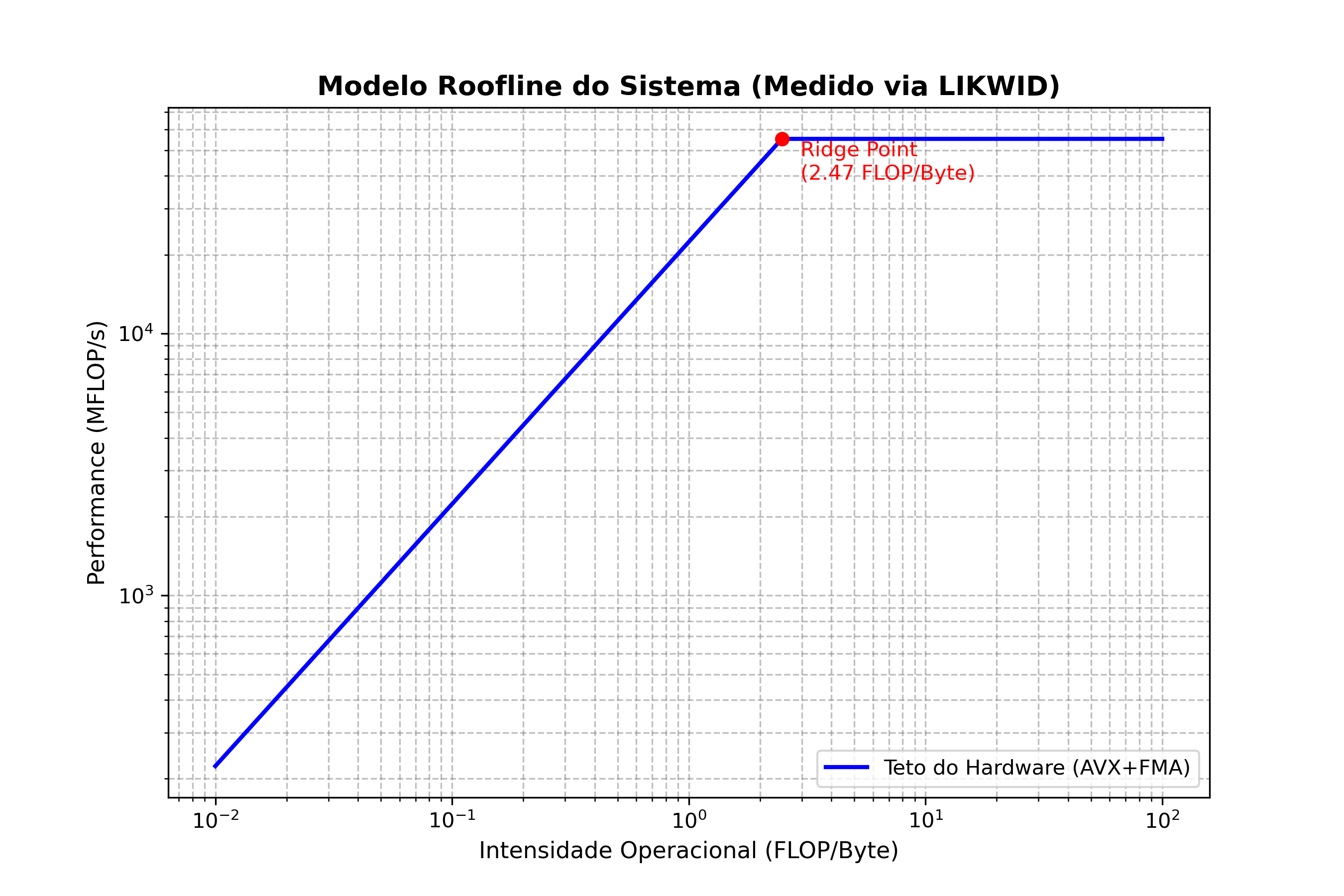
O teto computacional com instruções AVX+FMA utilizando 1 thread atingiu 55288.73 MFLOP/s (aproximadamente 55.29 GFLOP/s). Calculando o ridge point do sistema:
Plotando o teto puro do hardware gerado via script Python:
Análise da Aplicação: Norma Euclidiana
Com os parâmetros unicamente referentes ao hardware estabelecidos, vamos analisar a intensidade operacional para um código específico: a Norma Euclidiana de um vetor. A análise teórica do loop em C se baseia em:
for (size_t i = 0; i < VEC_SIZE; i++) {
soma_quadrados += vector[i] * vector[i];
}
Para cada elemento do vetor, o loop realiza exatamente 2 FLOPs (1 multiplicação e 1 adição de acumulação). Considerando um cenário com 50 milhões de elementos e 10 iterações, temos:
Como o vetor é do tipo double, cada elemento ocupa 8 Bytes. Lendo um elemento por iteração, o volume de dados movimentados é:
Resultando em uma Intensidade Operacional de:
A performance máxima esperada (Y) colada no teto para essa intensidade é:
Plotando o posicionamento final do algoritmo no gráfico:

Conclusão
Com isso, podemos verificar que o código está estritamente limitado pela largura de banda de memória desse hardware por estar bem à esquerda do ridge point. Para uma perfeita e máxima utilização de todo o hardware combinado, deveríamos buscar algoritmos com intensidade operacional igual ou maior que 2.47 FLOP/Byte.
Como a norma de um vetor lê muitos dados para fazer pouquíssimas contas, ela está fisicamente presa em 0.25 FLOP/Byte. Para mover uma aplicação em direção ao intervalo ideal, mudamos a estrutura do algoritmo usando técnicas como:
- Loop Tiling / Blocking: Dividir estruturas grandes em blocos menores que caibam inteiramente dentro dos caches L1/L2, reduzindo barramentos desnecessários à RAM principal.
- Fusão de Loops (Loop Fusion): Combinar operações diferentes sobre o mesmo vetor em um único laço, aproveitando que o dado já está nos registradores para aumentar o número de FLOPs por Byte trafegado.
Nesse momento não mostramos no gráfico nada sobre as linhas de utilização do cache para verificar como estava seu uso, talvez em um próximo artigo eu coloque algo para ficar claro o uso máximo deles também. Conclui-se que o Roofline ajuda bastante a entender os gargalos existentes no código e torna muito mais fácil a análise para otimização deles.
Referências
- [1] WILLIAMS, Samuel; WATERMAN, Andrew; PATTERSON, David. Roofline: an insightful visual performance model for multicore architectures. Communications of the ACM, v. 52, n. 4, p. 65-76, 2009.
- [2] HAGER, Georg; WELLEIN, Gerhard. Introduction to High Performance Computing for Scientists and Engineers. CRC Press, 2010.